What is the problem here?
A web page consists of an HTML page and (usually) various other files, such as stylesheets, scripts, and images. The basic model of page loading on the Web is that your browser makes one or more HTTP requests to the server for the files needed to display the page, and the server responds with the requested files. If you visit another page, the browser requests the new files, and the server responds with them.
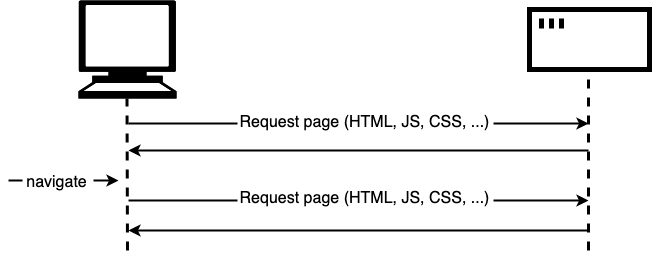
This model works perfectly well for many sites. But consider a website that's very data-driven. For example, a library website. Among other things you could think of a site like this as a user interface to a database. It might let you search for a particular genre of book, or might show you recommendations for books you might like, based on books you've previously borrowed. When you do this, it needs to update the page with the new set of books to display. But note that most of the page content — including items like the page header, sidebar, and footer — stays the same.
The trouble with the traditional model here is that we'd have to fetch and load the entire page, even when we only need to update one part of it. This is inefficient and can result in a poor user experience.
So instead of the traditional model, many websites use JavaScript APIs to request data from the server and update the page content without a page load. So when the user searches for a new product, the browser only requests the data which is needed to update the page — the set of new books to display, for instance.

The main API here is the Fetch API. This enables JavaScript running in a page to make an HTTP request to a server to retrieve specific resources. When the server provides them, the JavaScript can use the data to update the page, typically by using DOM manipulation APIs. The data requested is often JSON, which is a good format for transferring structured data, but can also be HTML or just text.
This is a common pattern for data-driven sites such as Amazon, YouTube, eBay, and so on. With this model:
- Page updates are a lot quicker and you don't have to wait for the page to refresh, meaning that the site feels faster and more responsive.
- Less data is downloaded on each update, meaning less wasted bandwidth. This may not be such a big issue on a desktop on a broadband connection, but it's a major issue on mobile devices and in countries that don't have ubiquitous fast internet service.
The Fetch API
There’s an umbrella term “AJAX” (abbreviated Asynchronous JavaScript And XML) for network requests from JavaScript. We don’t have to use XML though: the term comes from old times, that’s why that word is there. You may have heard that term already.
There are multiple ways to send a network request and get information from the server.
The fetch() method is modern and versatile, so we’ll start with it. It’s not supported by old browsers (can be polyfilled), but very well supported among the modern ones.
The basic syntax is:
let promise = fetch(url, [options]);url– the URL to access.options– optional parameters: method, headers etc.
Without options, this is a simple GET request, downloading the contents of the url.
The browser starts the request right away and returns a promise that the calling code should use to get the result.
Getting a response is usually a two-stage process. First, the promise, returned by fetch, resolves with an object of the built-in Response class as soon as the server responds with headers.
At this stage we can check HTTP status, to see whether it is successful or not, check headers, but don’t have the body yet.
The promise rejects if the fetch was unable to make HTTP-request, e.g. network problems, or there’s no such site. Abnormal HTTP-statuses, such as 404 or 500 do not cause an error.
We can see HTTP-status in response properties:
status– HTTP status code, e.g. 200.ok– boolean,trueif the HTTP status code is 200-299.
For example:
let response = await fetch(url);
if (response.ok) {
// if HTTP-status is 200-299
// get the response body (the method explained below)
let json = await response.json();
} else {
alert("HTTP-Error: " + response.status);
}Second, to get the response body, we need to use an additional method call.
Response provides multiple promise-based methods to access the body in various formats:
response.text()– read the response and return as text,response.json()– parse the response as JSON,response.formData()– return the response asFormDataobject (explained in the next chapter),response.blob()– return the response as Blob (binary data with type),response.arrayBuffer()– return the response as ArrayBuffer (low-level representation of binary data),- additionally,
response.bodyis a ReadableStream object, it allows you to read the body chunk-by-chunk, we’ll see an example later.
For instance, let’s get a JSON-object with latest commits from GitHub:
let url = "https://api.github.com/repos/Amcsui/frontend-bootcamp/commits";
let response = await fetch(url);
let commits = await response.json(); // read response body and parse as JSON
alert(commits[0].author.login);Or, the same without await, using pure promises syntax:
fetch(
"https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits"
)
.then((response) => response.json())
.then((commits) => alert(commits[0].author.login));